
Computer Vision: Attention or Convolution?
TL;DR
- Computer vision has traditionally relied on convolutional neural networks (CNNs) to process images efficiently.
- Vision transformers (ViTs) apply attention mechanisms to images, enabling global context across the entire image.
- CNNs often perform better in edge devices with limited compute, such as embedded medical systems.
- Transformers can scale more effectively for large datasets and cloud-based applications.
- Increasingly, hybrid architectures combining CNNs and transformers deliver the best performance for advanced AI applications.
Humans are highly visual creatures. Vision is generally perceived as the most important human sense and interplays with other senses in significant ways, mediating a gigantic proportion of our perception, learning, cognition, and day-to-day activities. It is also one of the easier senses to study, which has led to a glut of research into the visual modalities of memory and cognition.
Computer vision, a sub-field of artificial intelligence (AI), is the art of automating simple visual tasks with computers and has existed for over 50 years, utilizing a wide variety of techniques and methodologies. More recently, it has been augmented by the application of deep learning, which has benefited from gains in the processing power of graphic processing units (GPU)to significantly boost the accuracy of many computer vision tasks.
This is evident in the medical domain, with a significant proportion of AI-enabled medical devices being cleared for use in the radiological field, where they will assist in the interpretation of medical imaging. Advancements in the field will significantly improve the quality of these live-saving devices.
Convolutional neural networks (CNNs) are a class of neural network that has benefited immensely from improvements to GPU computing power. For a colour image with a resolution of 1920 x 1080, one would have over 2 million pixels of colour information, or 6 million individual values. A naive neural network, which links every pixel to a neuron, would need tens of millions or parameters as a baseline, and would struggle to identify an object from its training data if it was moved even several pixels over in the image!
Convolutional Neural Networks
Convolutions are a solution to this significant problem. CNNs learn sets of filters that are moved across the image to create “features” –highly-dimensional representations of the content. This makes the model significantly more location agnostic and drastically reduces the number of parameters required in the model.
CNNs are not without their shortcomings, however. The filters have limited widths, or receptive fields, which can limit the spatial extent that can be incorporated into a feature’s information. Broadening the receptive field requires broadening the filters, or deepening the network, which increases both the number of model parameters and the computational cost.
These limitations can have implications in an AI medical device, forcing a tradeoff between inference speed and model size, which can also have implications for the receptive field of the model, its ability to incorporate information from many disparate sources in an image, and the density of information that can be retained.
Vision Transformers
The attention mechanism has swiftly gained a significant share of modern machine learning (ML) techniques, through the transformer architecture. It demonstrated significant improvements over previous sequence-based techniques, including CNNs, in natural language tasks, leading to this architecture becoming the dominant design of large language models (LLMs).
A vision transformer (ViT) utilizes this architecture to process an image by first breaking it down into a sequence of “tokens” that represent chunks of the image processed by a neural network converter (which can be a one-layer CNN). Once the image has been converted into a sequence of tokens, the transformer backbone uses the features from within these tokens to modify the data for computer vision tasks (or for integration with a language-based transformer), weighting and mixing information from elements of the sequence based on its pre-training.
The transformer architecture itself is entirely linear operations, which modern GPUs are heavily optimized for. It also has the distinct advantage that any two tokens in the stream can be utilized by the network together with no additional overhead, removing the receptive field limitation.
This advantage over convolutional networks also comes with its own disadvantages. One transformer block contains many more parameters than a single convolutional layer. An attention block by itself can also only do bigram and skip-trigram style logic, with additional layers being required for more complex tasks.
The memory requirements for a transformer model also scale by the square of the sequence length, compared to the requirements for convolutional models, which scale linearly with input pixels.
In a medical device, especially on the edge, where compute resources are limited, this memory tradeoff may not be ideal. ViTs also typically require pre-training to outperform other modern architectures in a specific domain, which may have implications in a regulatory environment that requires chain of custody for data used to develop medical devices.
Head to Head
Both convolutional and transformers-based architectures are capable of achieving state-of-the-art performance for computer vision tasks.
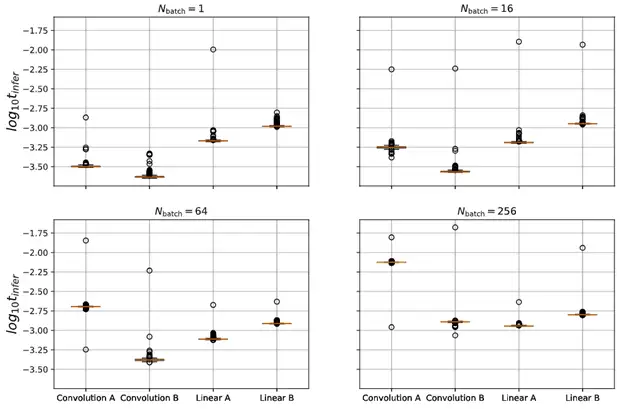
A significant downside of convolutional models is that they are slower to train than models based on linear operations, such as transformers. This is due primarily to the effect of batch size, the number of examples to feed through the model at once, on the time required to perform inference. Large batch sizes are important during training to help average out the effects of individual examples on the model’s behaviour.
In benchtop experimentation (Fig 1.), four different architectures were tested head-to-head with varying batch sizes. Convolution A is adjusted to have the same number of parameters as the Linear A and Linear B models, while Convolution B is adjusted to have roughly the same number of multiplication and addition steps as the linear models (necessitating 100X fewer parameters). Linear A is wide-but-shallow a vision transformer, while Linear B is a narrow-but-tall architecture.
At low batch sizes, convolutional models are faster by roughly 4X, however as the number of concurrent inputs increases, the performance of linear models remains very consistent, while that of convolutional architectures falls off more sharply.
This is important, because the ability to train a model on more data in the same amount of time can allow a company to reach state-of-the-art earlier. Additionally, the ability to perform inference on many more inputs at once without a significant speed penalty can allow a company to scale their services more aggressively.
Conclusion
While convolutional and transformer-based models can both reach incredibly high accuracies, their relative strengths and weaknesses guide the best deployment options. Convolutional models might be ideal for a device with a local ML component, which will act on a single example at a time, where it can provide blazing fast performance. A vision transformer may, however, scale better for cloud services, and could also provide benefits in situations where the receptive field of convolutional methods becomes a liability instead of a feature.
The future lies between the two; maximal performance has come from models that combine the two architectures, utilizing the strong feature extraction abilities of CNNs with the non-local information processing abilities of transformers. As these techniques are further investigated and refined, we can expect a growing number of next-generation medical devices to benefit.
Thor Tronrud, PhD, is a Senior Machine Learning Scientist at StarFish Medical who specializes in the development and application of machine learning tools. Previously an astrophysicist working with magnetohydrodynamic simulations, Thor joined StarFish in 2021 and has applied machine learning techniques to problems including image segmentation, signal analysis, and language processing.
Images: Adobe Stock
Related Resources

Medical device teams developing embedded and cross-platform GUIs can accelerate delivery without compromising usability or validation by choosing the right framework early and designing for performance, portability, and maintainability.

Compute demands on “the edge”, like embedded sensors or remote devices. have grown significantly as AI has moved from experimentation to deployment. Medical devices are pushing more of their AI functionality onto edge hardware.

Medical device cleaning is more complex than it seems. In this Bio Break episode, Nick and Nigel unpack what really goes into cleaning medical devices and why it cannot be treated like a simple wipe-down process.

This blog reviews the main families of optical detectors and the major technologies in those families.