
Enabling Faster AI on the Edge
TL;DR
- CMSIS-DSP provides optimized DSP and math functions for edge AI on Arm Cortex devices
- It speeds up development and improves performance with hardware-aware implementations
- Benchmarks show strong gains, especially in filters and linear algebra operations
- Use it as a default, then optimize with custom code where performance gains justify it
CMSIS-DSP in Real Firmware AI Pipelines
Compute demands on “the edge”, like embedded sensors or remote devices. have grown significantly as AI has moved from experimentation to deployment. Medical devices are pushing more of their AI functionality onto edge hardware. No matter the inference task at hand, the core of most edge-AI systems is an embedded microcontroller running a digital signal processing (DSP) pipeline.
For Arm-based systems, the CMSIS-DSP library is a standout candidate full of useful DSP and AI building blocks. It’s powerful, mature, and widely used, but it’s not a silver bullet. When used well, it saves engineering time; however, if it’s applied blindly, it can cost memory, performance, and code clarity.
Let’s look at the CMSIS-DSP library from the perspective of shipping firmware with DSP pipelines that now increasingly blur into edge AI inference: what it is, why it’s useful, and where its abstractions stop being a good fit.
What is the CMSIS-DSP Library?
The Common Microcontroller Software Interface Standard (CMSIS), is Arm’s low-level hardware abstraction layer for Cortex-class processors. Most teams encounter it indirectly with vendor hardware abstraction layers (HALs) typically sitting on top of it. CMSIS-DSP extends CMSIS by adding a large collection of DSP, linear algebra, and math routines.
The CMSIS-DSP library is open source, actively maintained, and integrates easily into firmware projects that already use CMSIS. It includes vector and matrix math, FIR and IIR filters, statistics, transforms such as FFTs and more. These routines go beyond portable C implementations and are optimized specifically for the Arm Cortex architecture.
CMSIS-DSP is portable across the Cortex-M and Cortex-A families, and it’s optimized to take advantage of each core’s compute abilities. On a Cortex-M0+ with no hardware FPU, CMSIS-DSP can use fixed-point math to avoid software-emulated floating point. On a Cortex-M4, it uses the DSP instructions and hardware floating point. On newer cores with Helium or Neon, it exploits vector operations and wider Single Instruction, Multiple Data (SIMD) lanes. These optimizations matter not just for classic DSP, but also for edge AI workloads that are built on the same underlying primitives: dot products, matrix multiplies, vector scaling, and nonlinearities.
Why CMSIS-DSP Is a Good Default Toolbox
The main value of CMSIS-DSP isn’t that it beats every custom algorithm you could write, it’s that it gives you a solid baseline of well-tested, hardware-aware implementations that you don’t have to maintain.
Many DSP-heavy firmware projects end up re-implementing the same basic primitives: vector scaling, dot products, matrix multiplies, filters, and FFTs. The same is true for edge AI pipelines, especially lightweight inference and classical ML models running alongside traditional signal processing. CMSIS-DSP already has these primitives, and they’re generally faster than naive implementations because they exploit the architecture properly.
Another practical advantage is architectural flexibility. If your product line spans multiple Arm cores, or you expect it might in the future, CMSIS-DSP lets you keep the DSP pipeline stable while the hardware underneath changes. The same API spans everything from low-power embedded MCUs to application-class processors.
The trade-off is that the library is necessarily generic. It can’t know the exact structure of your pipeline or the assumptions you’re willing to make.
Build and Test Integration Is Easier Than It Used to Be
CMSIS-DSP builds cleanly with CMake. If your firmware already uses CMake, integrating it is straightforward: build it as a static library and link against it.
There are also compile-time switches that you can tweak. You can disable float16 support if your core doesn’t have it, enable or disable loop unrolling, and configure support for Neon or Helium. These flags materially affect both performance and code size.
For unit testing, there’s a particularly useful feature. When building for the host PC (meaning not cross-compiling), you can set HOST=ON in your CMake build, replacing Arm-specific instructions with standard C implementations. You can then exercise your entire embedded AI pipeline on a desktop without stubbing out the CMSIS-DSP calls.
You still need on-target testing, but this dramatically simplifies numerical pipeline and numerical validation before moving to the more isolated embedded environment.
Benchmarking
We benchmarked CMSIS-DSP against several common “homemade” routines on a Cortex-M4 with an FPU and DSP extensions. The takeaway is that CMSIS-DSP is a strong default choice, but specialization still matters. The examples below show highlight both sides of that trade-off.
Biquads: Where CMSIS-DSP Shines
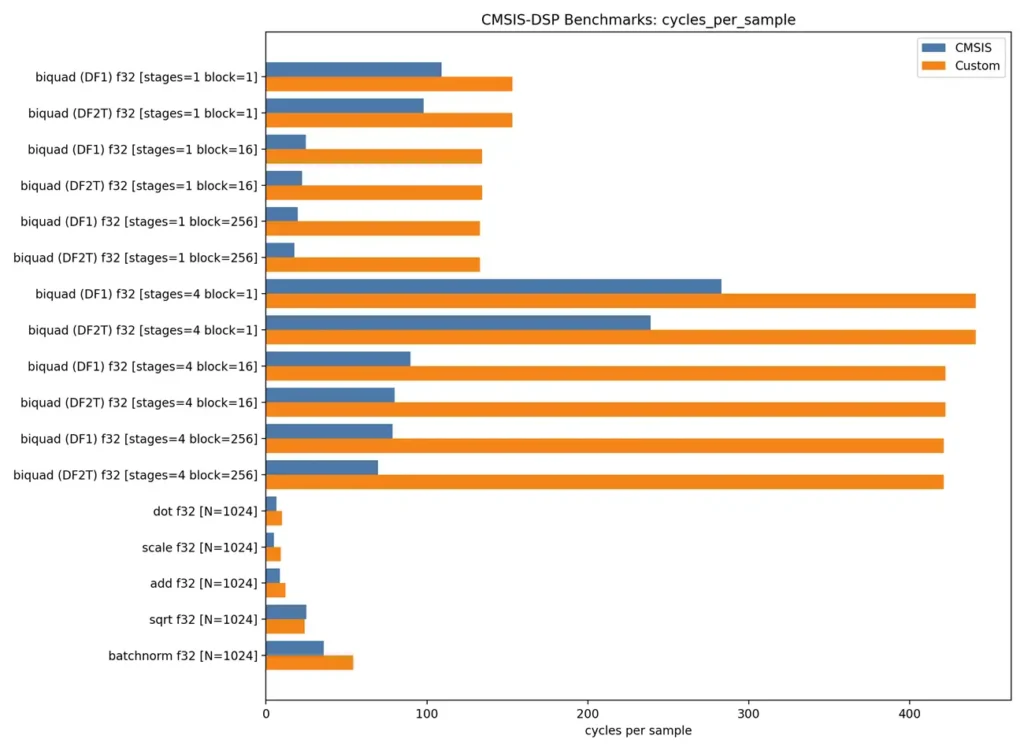
Bi-quadratic filters, commonly “biquads,” are versatile second-order filters which are used in stages to build stable higher-order filters. CMSIS-DSP provides biquad filters with built-in support for cascading stages and processing blocks of samples. Compared to a custom biquad designed for streaming one sample at a time, performance is similar. With minor tweaks, the custom implementation will beat out CMSIS-DSP in that narrow case.
As soon as you increase block size or add cascaded stages, CMSIS-DSP pulls ahead. In our benchmarks, it required roughly 7x fewer cycles per sample. This is particularly relevant when filters are part of a feature extraction pipeline feeding an ML model, where batching samples can dramatically reduce overall compute cost. You could extend the custom implementation to do the same, but that’s more development time and more code to maintain.
Boxcar Filters: Identifying When to Go Custom
A boxcar filter is one of the first tools that a firmware engineer reaches for when smoothing sampled data. CMSIS-DSP doesn’t have a specialized boxcar filter. It does provide a generic finite impulse response (FIR) filter, which you can use to implement a boxcar filter by setting all taps to 1/N.
A boxcar filter only changes by adding one sample and removing one sample each step. A sliding-window implementation can do this with a single add, subtract, and divide per output. Compared against CMSIS-DSP’s FIR filter, the custom boxcar was about 10x faster.
This is a good example of where CMSIS-DSP’s generality works against it. The library can’t assume you’re doing a boxcar, so it can’t exploit the structure. If your problem has exploitable structure, you should use it.
Linear Algebra: The Core of Edge AI
We benchmarked matrix multiplication, dot products, vector scaling, and vector addition. CMSIS-DSP was about 1.5x faster across the board compared to a more generic C implementation. This matters because it highlights where the speedup comes from. CMSIS-DSP isn’t doing anything exotic. It’s just doing the obvious low-level optimizations consistently and correctly.
This is the heart of many edge AI workloads: simple feed-forward networks are built almost entirely from these primitives. The flagship models of the AI industry, large language models (LLMs), are built with many feed-forward layers comprised of these basic linear algebra operations.
CMSIS-DSP doesn’t replace a full ML framework, it provides efficient, predictable implementations of the math that those frameworks ultimately rely on.
Stacking linear algebra primitives into an example edge AI pipeline reinforced these results. With its aggressive loop unrolling options enabled, the CMSIS-DSP pipeline was about 50 percent faster than the in-house version. Without it, it was still about 10 percent faster. For on-device inference, that difference often determines whether a design meets real-time and power constraints.
See the figure below for a comparison between the CMSIS-DSP and a custom implementation for the biquad and linear algebra routines. The graph charts “processor clock samples per cycle” so a smaller bar is better.
Sidebar: CMSIS-NN vs CMSIS-DSP
You can’t talk about edge AI on Arm Cortex without mentioning their neural-network-specific library, CMSIS-NN. While we’ve been focusing on the front-end and building blocks for a pipeline, CMSIS-NN is tailored specifically for building neural networks on a Cortex-M processor. Its kernels assume specific data layouts, fixed-point representations, and layer semantics. That structure is what enables its performance, but it also concentrates complexity. From a regulatory standpoint, that complexity has to be justified, documented, and verified as part of the device’s software safety case.
CMSIS-DSP, by contrast, provides mathematical primitives. Filters, transforms, vector math, and linear algebra routines are easier to reason about, easier to test in isolation, and easier to validate against known-good references. When used for feature extraction, normalization, or simple feed-forward stages, CMSIS-DSP allows tighter control over numerical behavior and failure modes.
CMSIS-DSP fits naturally where deterministic behavior, transparency, and testability matter most. Introduce CMSIS-NN when the benefits of model-based inference clearly outweigh the added complexity. These two libraries are best seen as two different toolkits operating at different layers in the same stack. A deeper discussion of CMSIS-NN is a topic of its own.
Use CMSIS-DSP as the Default, Then Specialize
CMSIS-DSP is not a drop-in replacement for thinking about your edge AI pipeline. It’s a high-quality toolbox. If you start with it as the default, you avoid re-writing a lot of routine code. You also gain portability across Arm cores and access to hardware-specific optimizations by default.
But it’s generic by design. When your problem has special structure that you can exploit, a custom solution may be the right call.
A pattern that works well is to use CMSIS-DSP by default, then measure and drill into the individual pieces where the data shows a clear win. That keeps the amount of bespoke DSP code small, focused, and justified.
If you are targeting an Arm processor and you are building edge AI feature extraction, inference, or classic DSP pipelines, CMSIS-DSP is a strong place to start. Treat it as a starting point and stay on top of measuring performance, and you’ll get the best of both worlds.
Levi Puckett is a Software Engineer at StarFish Medical. With a degree in Electrical Engineering, he bridges the gap between electronics and high-quality embedded software. Levi works at all levels of medical device software, helping companies develop effective, innovative, and safe software for their new medical devices.
Images: Adobe Firefly
Related Resources

Medical device teams developing embedded and cross-platform GUIs can accelerate delivery without compromising usability or validation by choosing the right framework early and designing for performance, portability, and maintainability.

Compute demands on “the edge”, like embedded sensors or remote devices. have grown significantly as AI has moved from experimentation to deployment. Medical devices are pushing more of their AI functionality onto edge hardware.

Medical device cleaning is more complex than it seems. In this Bio Break episode, Nick and Nigel unpack what really goes into cleaning medical devices and why it cannot be treated like a simple wipe-down process.

This blog reviews the main families of optical detectors and the major technologies in those families.